Author
 |
 |
 |
| Yangyu Huan | Qingyao Xu | Han Lu |
Scene understanding has always been a topic for researches. Some models on scene understanding have been made to extract information from images such as semantic parsing and spatial position. However, few models can present a general but intuitive impression on the input image. To improve this situation, we propose our architecture: human-in-loop Multi-task Driven Network(MD-Net), aiming to give the layering of images' spatial structure. MD-Net consists of an encoder for the input and two decoders for two auxiliary tasks, and finally a convolution layer to generate the output prediction. Our model can run with humans selecting good results from new unseen datasets in each loop to enrich the training dataset and improve performance. Our network is proved to be effective and can generate new datasets effciently. The code, model, and dataset are publicly available.
|
|
|
| Yangyu Huan | Qingyao Xu | Han Lu |
Our paper is available here.
Our source code is available on Github.
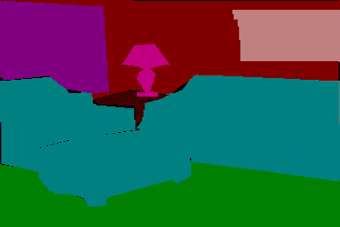
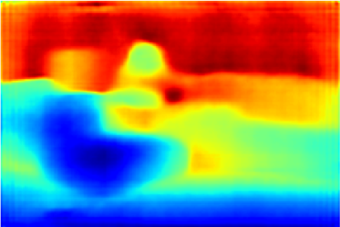
We construct our dataset from Sun-dataset. Our task is generating indoor layering prediction. Since there's no dataset about this task, the ground truth for our task is generated by ourselves using a specific rule with the help of depth and segmentation information.
 |
 |
 |
 |
| input image | segmentation | depth | Groung Truth |
 |
 |
 |
 |
| input image | |||
 |
 |
 |
 |
| output image | |||